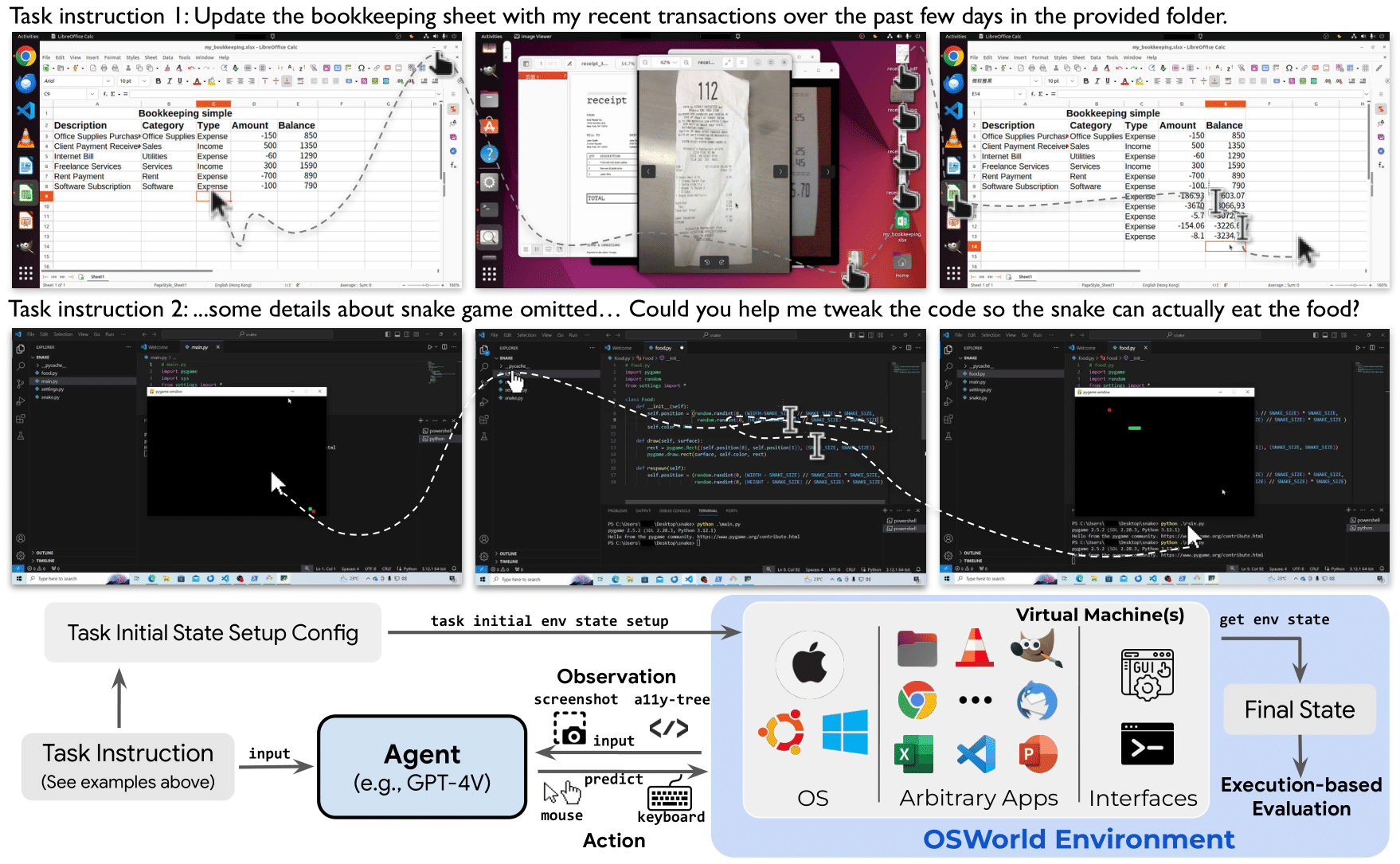
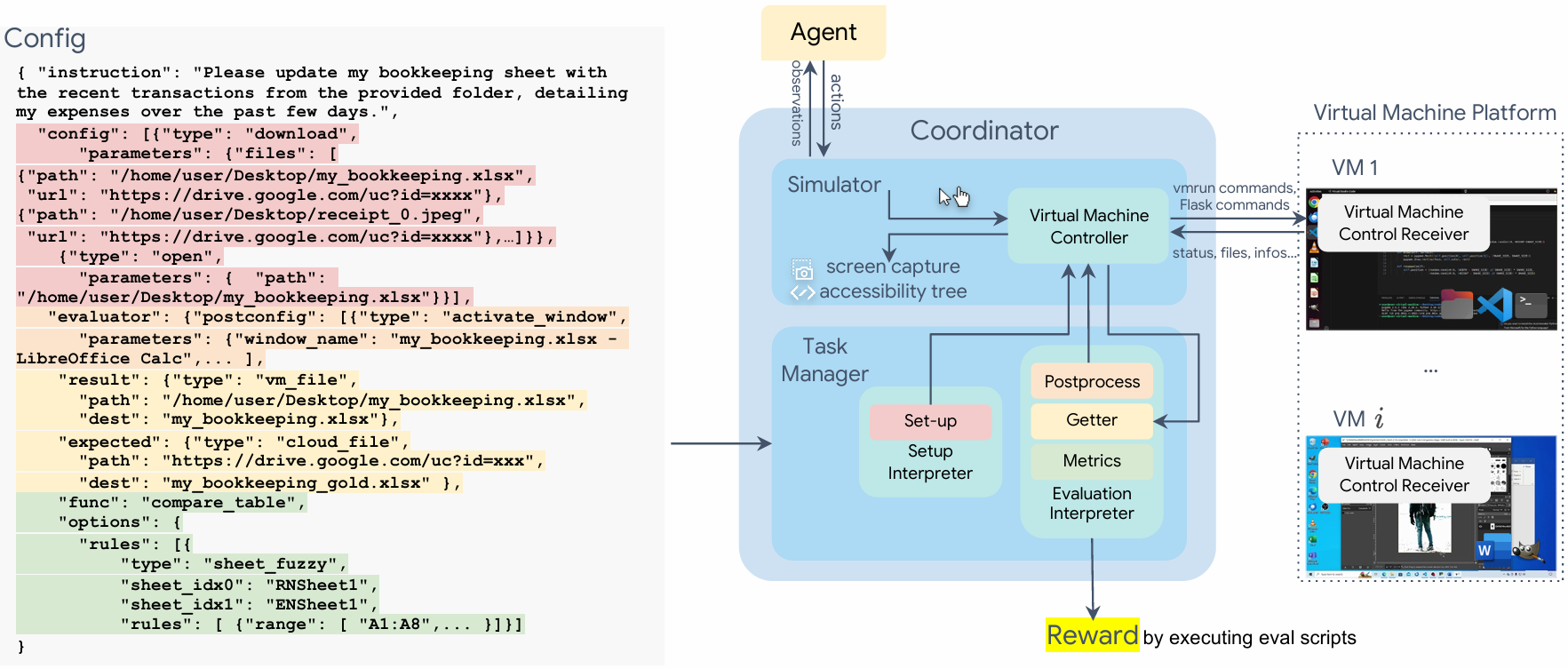
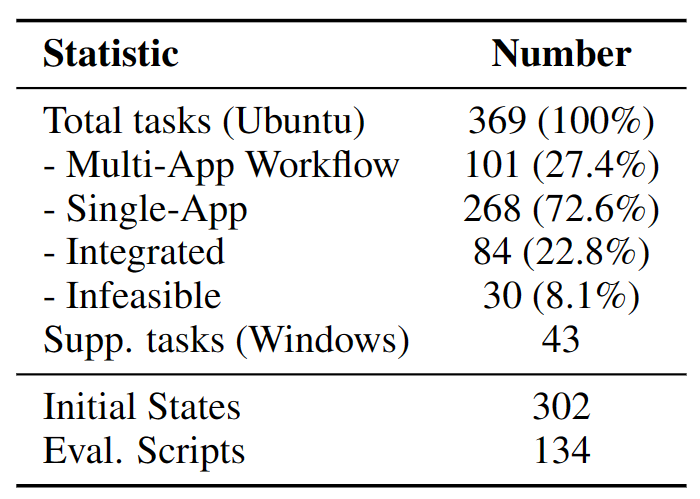
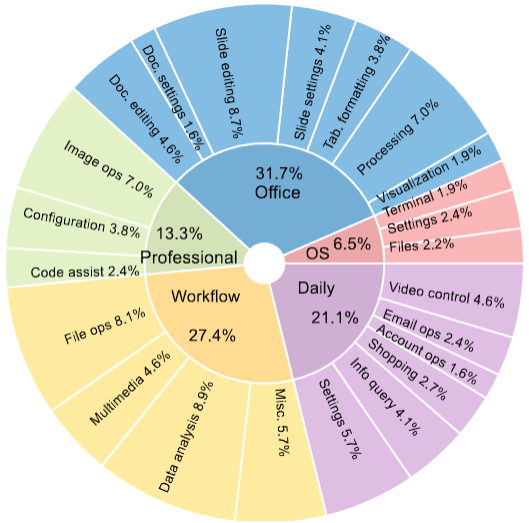
Distribution of task instructions in OSWorld
based on the app domains and operation
types to showcase the content intuitively.
| OSWorld | |
|---|---|
| # Instances (# Templates) |
369 |
| Control. Exec. Env. |
Computer |
| Environment Scalability? | ✔️ |
| Multimodal Support? |
✔️ |
| Cross-App? | ✔️ |
| Intermediate Init. State? |
✔️ |
| # Exec.-based Eval. Func. |
134 |
| GAIA | Mind2Web | WebLINX | PixelHelp | MetaGUI | AitW | OmniAct | ScreenAgent | AgentBench | InterCode | MiniWoB++ | WebShop | WebArena | VisualWebArena | WorkArena | WikiHow | AssistGUI |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 466 |
2350 | 2337 | 187 | 1125 | 30k | 9802 | 70 | 1091 | 1350(3) | 125 | 12k(1) | 812(241) | 910(314) | 23k(29) | 150(16) | 100 |
| ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | Multi-isolated | Code | Web | Web | Web | Web | Web | Mobile | ❌ |
| - | - | - | - | - | - | - | - | ❌ |
❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| ❌ |
✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ❌ | ❌ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| ❌ | ✔️ | ✔️ | ❌ |
❌ | ✔️ | ✔️ | ✔️ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ✔️ | ❌ | ✔️ |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 7 | 3 | 125 | 1 | 5 | 6 | 7 | 16 | 2 |
OSWorld contains 8 Google Drive-related tasks that may encounter setup issues during task initialization due to IP changes or other network-related factors, even when following our configuration guidelines correctly.
Two acceptable approaches for evaluation:
Both approaches are valid for benchmark comparison and leaderboard submission.
These are official results evaluated by our team under unified settings and environment. All models are tested with consistent evaluation protocols to ensure fair comparison.
For self-reported results and progress trends across different modalities, click here.
All verified trajectories are hosted on Hugging Face for community analysis.
Loading verified benchmark data...


We thank Sida Wang, Peter Shaw, Alane Suhr, Luke Zettlemoyer, Haoyuan Wu, Junli Wang, Chengyou Jia, Junlin Yang, Junlei Zhang, Chen Henry Wu, Pengcheng Yin, Shunyu Yao, Xing Han Lu, Siva Reddy, Ruoxi Sun, Zhiyuan Zeng, and Lei Li for their helpful feedback on this work
The username and password for the virtual machines are as follows (for provider vmware, virtualbox and docker): we set the account credentials for Ubuntu as user / password.
For cloud service providers like aws, to prevent attacks due to weak passwords, we default to osworld-public-evaluation.
If you make further modifications, remember to set the client_password variable and pass it to DesktopEnv and Agent (if supported) when running experiments.
Some features like setting up proxy require the environment to have the client VM password to obtain sudo privileges, and for some OSWorld tasks, the agent needs the password to obtain sudo privileges to complete them.
OSWorld contains 8 Google Drive-related tasks that may encounter setup issues during initialization due to various factors:
Common Issues:
See Setup Guideline - Proxy Configuration.
We also provide a pre-configured solution based on DataImpulse, please refer to proxy setup section.
@misc{OSWorld,
title={OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments},
author={Tianbao Xie and Danyang Zhang and Jixuan Chen and Xiaochuan Li and Siheng Zhao and Ruisheng Cao and Toh Jing Hua and Zhoujun Cheng and Dongchan Shin and Fangyu Lei and Yitao Liu and Yiheng Xu and Shuyan Zhou and Silvio Savarese and Caiming Xiong and Victor Zhong and Tao Yu},
year={2024},
eprint={2404.07972},
archivePrefix={arXiv},
primaryClass={cs.AI}
}